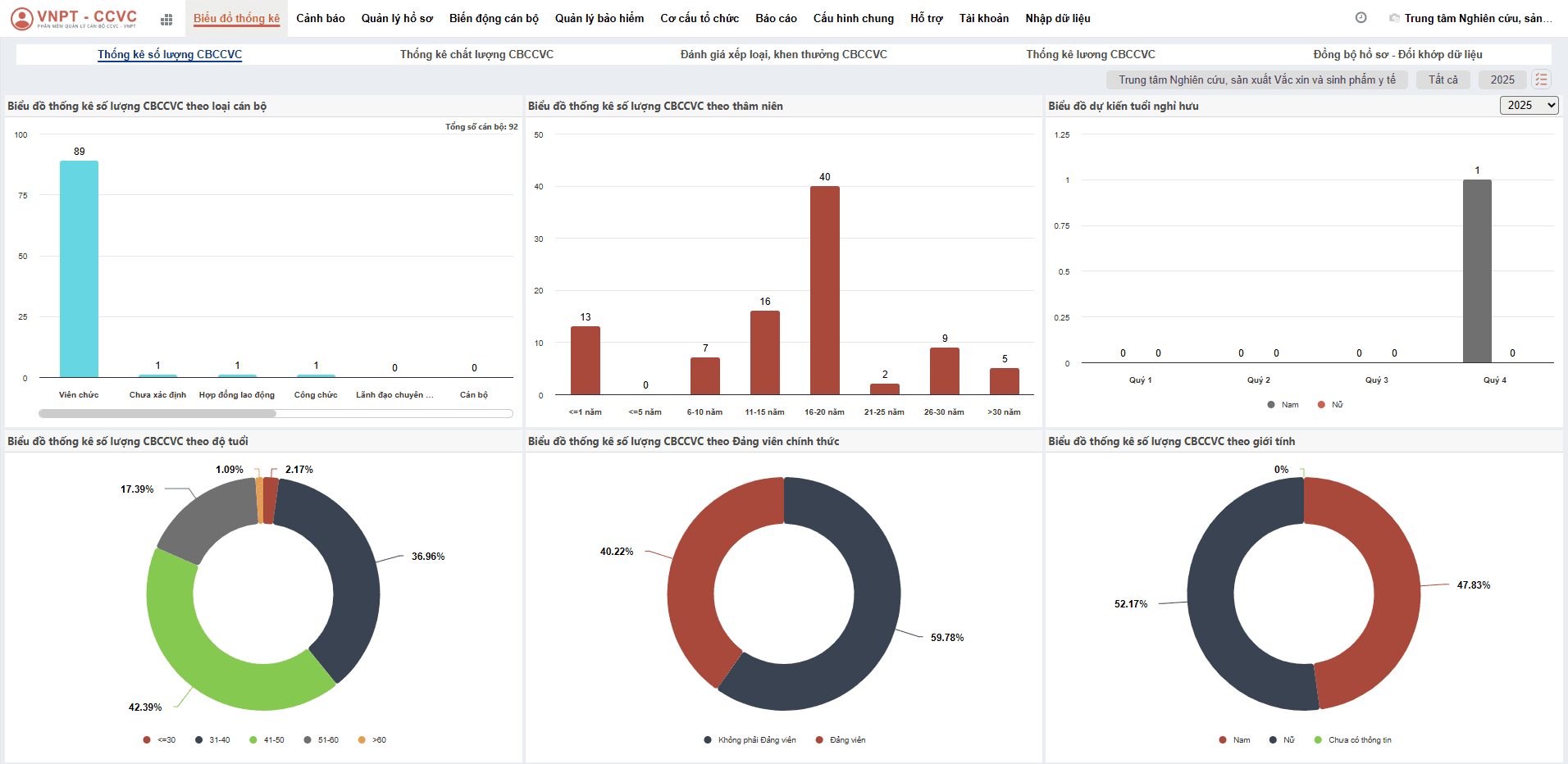
VNPT IDMA là giải pháp phân tích dữ liệu kinh doanh thông minh cung cấp đầy đủ các module chức năng phục vụ cho các nghiệp vụ: quản trị người dùng, quản trị gói cước, thanh toán, quản trị tổ chức, quản lý vùng làm việc theo workspace. Trong mỗi workspace sẽ đáp ứng được các nghiệp vụ: quản lý dữ liệu, thu thập dữ liệu, truy vấn dữ liệu, vẽ dashboard, khoa học dữ liệu, quản lý tài nguyên…
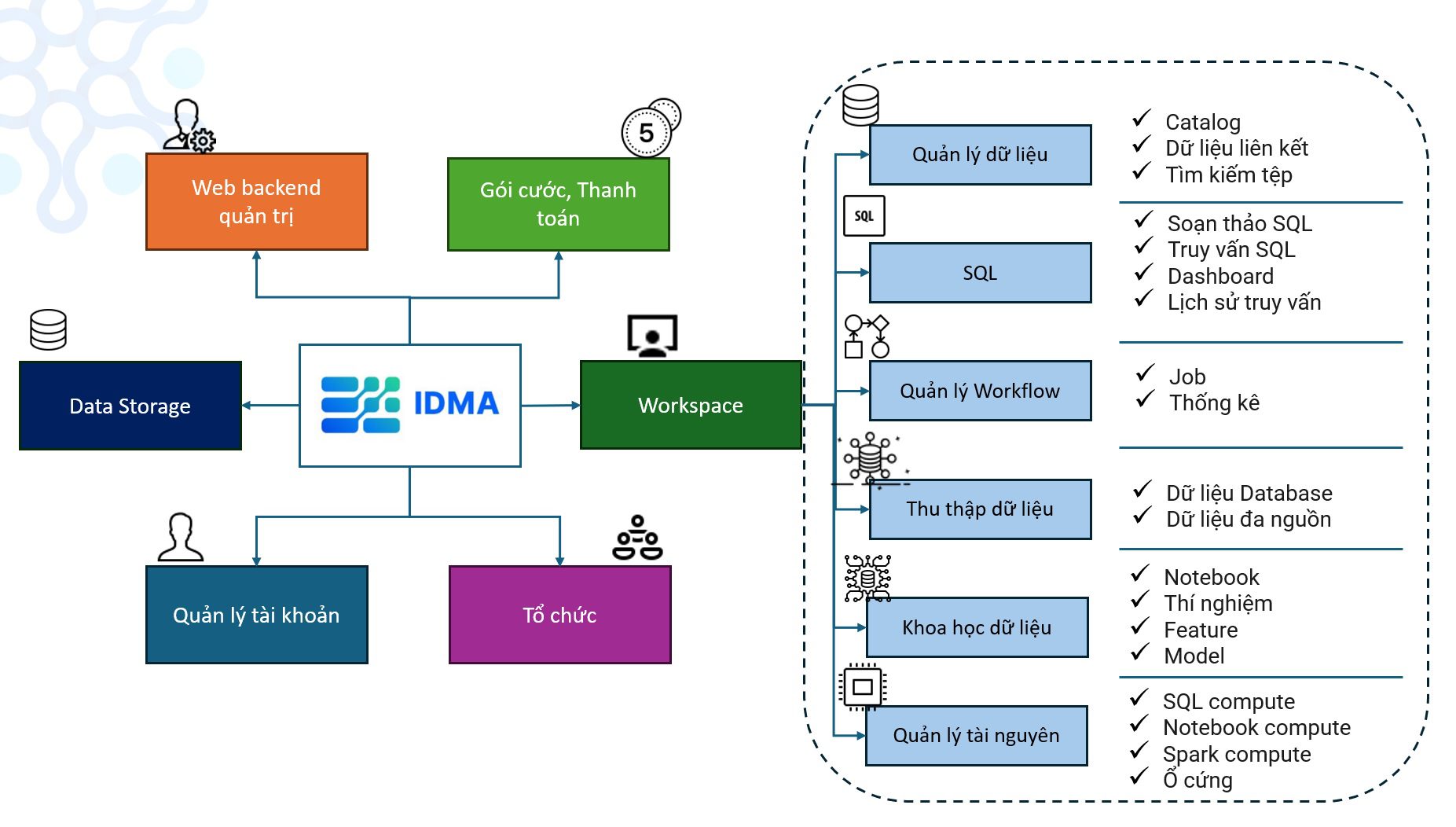
Kiến trúc hệ thống VNPT IDMA

+ Lớp thu thập dữ liệu: thu thập dữ liệu có cấu trúc (database, csv, excel…), dữ liệu phi cấu trúc (dữ liệu tệp). Thu thập dữ liệu theo thời gian thực hoặc theo định kỳ đặt lịch.
+ Lớp lưu trữ dữ liệu: dữ liệu thu thập về được lưu trữ trong các hộp dữ liệu (đối với dữ liệu tệp) hoặc tổ chức thành các catalog (đối với dữ liệu dạng bảng)
+ Lớp xử lý dữ liệu: dữ liệu lưu trữ về được xử lý bằng các công nghệ như Spark, bash, notebook, sql editor…tích hợp trong các workflow
+ Lớp khai thác dữ liệu: sử dụng các lớp công nghệ về BI để trực quan hóa dữ liệu, công nghệ về khoa học dữ liệu để ứng dụng machine learning… Cho phép chia sẻ dữ liệu ra bên ngoài bằng API.
Các Module chức năng
Tổ chức

- Mỗi tài khoản người dùng được tạo 1 tổ chức hoặc tham gia vào tổ chức người khác
- Tổ chức phải có sự phê duyệt của Admin quản trị
- Quản trị tổ chức có thể thêm người dùng vào tổ chức, phân vai trò cho người dùng
- Quản trị tổ chức có thể tạo ra các Workspace để tạo các không gian làm việc riêng cho từng dự án và thêm người dùng vào các Workspace
Data Storage
là nơi sắp xếp và quản lý lưu trữ dữ liệu. Phân quyền khai thác sử dụng nơi lưu trữ bằng cặp khóa truy cập. Các chức năng chính gồm có:

- Quản lý Bucket: Tạo ra các cấp quản lý lưu trữ cao nhất. Cấu hình được dung lượng lưu trữ cho Bucket
- Quản lý dữ liệu tệp: Sắp xếp, cấu trúc dữ liệu trong các Bucket dạng thư mục. Cho phép upload tệp dữ liệu, chia sẻ ra bên ngoài
- Quản lý Khóa truy cập: Quản lý các cặp khóa để phân quyền khai thác và sử dụng Bucket
Catalog

- Là nơi sắp xếp tổ chức dữ liệu bảng. Dữ liệu được thu thập từ nhiều nguồn khác nhau có thể được nhóm vào chung 1 catalog để khai thác. Khi đó sẽ giải quyết được vấn đề dữ liệu rời rạc.
- Dữ liệu trong catalog được sắp xếp trong các cấp độ nhỏ hơn gồm: Catalog và Bảng.
- Dữ liệu Bảng có thể được tải lên từ tệp có cấu trúc (csv, xlsx…) hoặc được thu thập từ các nguồn khác nhau (database, Google sheet…)
Dữ liệu liên kết

- Là nơi khai báo các hộp dữ liệu để lưu trữ dữ liệu trong Data Storage. Mỗi hộp dữ liệu bao gồm các Bucket được cấp quyền bởi cặp khóa gắn với hộp dữ liệu.
- Toàn bộ dữ liệu của Workspace sẽ được lưu trữ trong cac hộp dữ liệu được khai báo trong Workspace đó
Quản lý Workflow: Job

- Người dùng có thể tạo Job để quản lý chu trình xử lý công việc. Mỗi Job sẽ định nghĩa một chu trình.
- Một Job có thể có nhiều task. Mỗi task thực hiện một nhiệm vụ nhất định như: Truy vấn SQL, chạy code python, gửi email, chạy API…
- Job có thể được kích hoạt thủ công hoặc kích hoạt chạy theo lịch
- Người dùng có thể xem lại thống kê lịch sử các lần chạy. Tra cứu log
Thu thập dữ liệu nguồn Database
cho phép tạo các kết nối để đồng bộ dữ liệu từ database về kho dùng chung:

- Dữ liệu được đồng bộ tức thời khi có các thay đổi từ dữ liệu nguồn
- Hỗ trợ các loaid database dữ liệu nguồn phổ biến như: MySQL, PostgreSQL, Oracle, MongoDB
- Cấu hình lưu trữ dữ liệu trong các catalog
- Cấu hinh các tham số kết nối để tối ưu hoạt động
Thu thập dữ liệu đa nguồn

- Cho phép tạo các kết nối để đồng bộ dữ liệu từ các nguồn dữ liệu khác ngoài database như: Google Sheet, API… về kho lưu trữ chung và tổ chức trong các catalog.
- Dữ liệu từ các nguồn này sẽ được tự động chuyển đổi thành các bảng dữ liệu có cấu trúc lưu trữ trong catalog.
- Quá trình đồng bộ được kích hoạt thủ công hoặc định kỳ theo lịch
Phân hệ SQL
cho phép:

- Truy vấn và tương tác với dữ liệu qua giao diện của SQL editor
- Trực quan hóa dữ liệu bằng các đồ thị BI thời gian thực
- Tra cứu lịch sử truy vấn dữ liệu
- Tạo lập các Dataset từ nhiều bảng rời rạc phục vụ cho phân tích và vẽ đồ thị
Phân hệ Khoa học dữ liệu

- Thực hiện chức năng khai phá và phân tích dữ liệu lớn bằng các công cụ như notebook, model AI…
- Ứng dụng phân hệ Khoa học dữ liệu giúp giải quyết được các bài toán phân tích dữ liệu lớn và các bài toán AI về phân tích dự đoán, phân loại, phân nhóm…
- Hiện tại chức năng quản lý notebook đã được phát triển cho phép người dùng tự tạo các notebook, xử lý dữ liệu bằng notebook, theo dõi log trạng thái hoạt động của notebook.
Phân hệ Quản lý tài nguyên
Cho phép người dùng thực hiện tạo mới và quản lý các tài nguyên phần cứng cần thiết trong quá trình sử dụng IDMA như:

- Kho SQL: Tài nguyên phục vụ chạy các lệnh SQL
- Spark compute: Tài nguyên phục vụ chạy ứng dụng Spark
- Notebook compute: Tài nguyên phục vụ chạy notebook
- Ổ cứng: Tài nguyên phục vụ lưu trữ dữ liệu của notebook hoặc Spark
- Người dùng có thể cấu hình dung lượng của tài nguyên theo các lựa chọn từ thấp đến cao tùy theo nhu cầu.
Báo giá
Liên hệ